


Я пользуюсь Дзенмани (https://zenmoney.ru/) для учета расходов. Меня это приложение всем устраивает, но не хватает там подкачки траназкций из самого сбер спасибо.
Подкачка событий о карте работает по СМС-кам, а вот стягивать кешбечные транзакции не выходит.
Учитывая, что сберспасибо мне капает достаточно много и операций по ним у меня уже приличное количество (самокат, купер, мегамаркет), я решил себе сделать интеграцию.
Как стягивать данные
Теория
Для стягивания данных пойду по пути подключения к уже включенному браузеру. Авторизация в сбере не из простых и её реализовывать на уровне апишек будет крайне непросто.
Поэтому просто беру отдельный браузер на моем рабочем компе, запущенный с уже проведенной руками авторизацией и стягиваю данные.
Если авторизация слетит, то я руками также спокойно её проделаю на компе и интеграция заработает дальше.
Страница, которая будет парситься — https://spasibosberbank.ru/lk_history
Формат данных
Надо будет реагировать на события XHR запросов к адресу
https://spasibosberbank.ru/api/online/personal/loyalitySystem/transactions?page=1&cnt=100
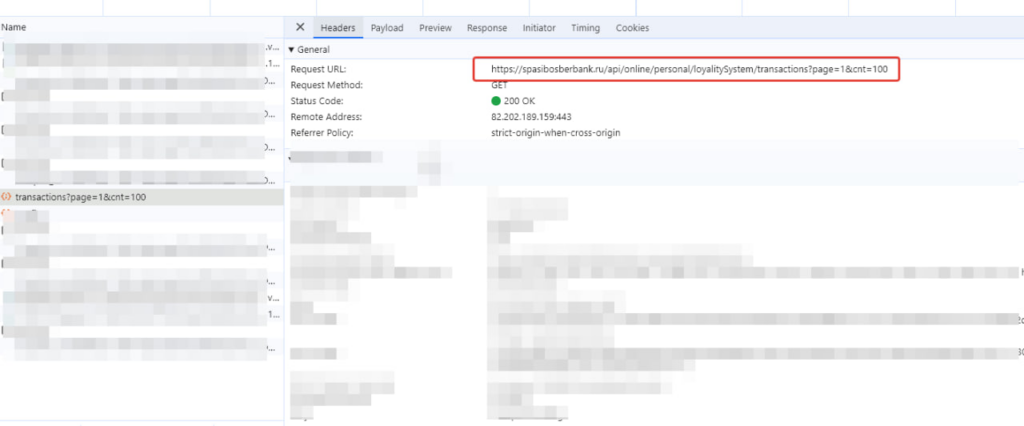
100штук мне хватит, учитывая что стягивание транзакций будет происходить раз в сутки, а за сутки больше 100шт я не наберу.
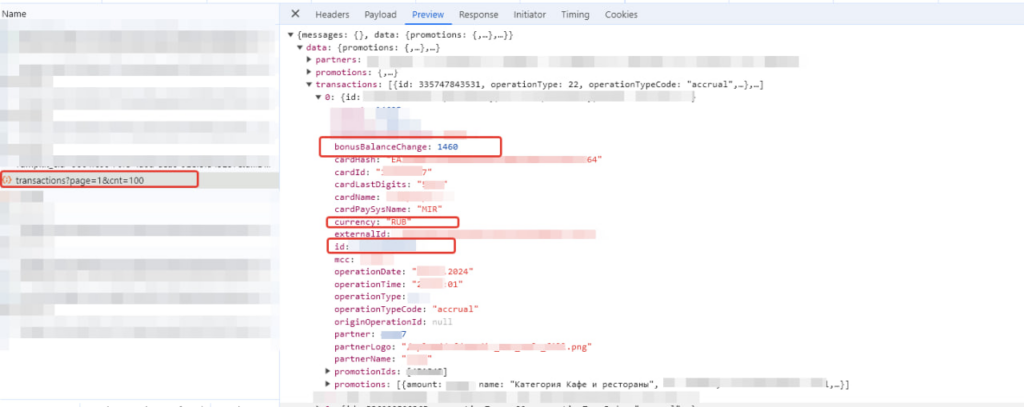
Нужные поля уже выявлены. Выделил их на скрине красным
Первый успешный запуск и получение данных
По инструкции отсюда запустил браузер и запустил код для получения данных. Данные стягиваются успешно. Код для стягивания данных:
public async fetchTransactions(): Promise {
const browser = await this.puppeteerService.getLocalBrowser();
const page = await browser.newPage();
try {
const promise = new Promise((resolve, reject) => {
page.on('response', async (response) => {
const url = response.url();
if (
url.includes(
`https://spasibosberbank.ru/api/online/personal/loyalitySystem/transactions`,
)
) {
if (response.status() === 200) {
const data = await response.json();
this.logger.log(`Data. ${data.data.length}`);
resolve(data.data);
} else {
this.logger.log(`Error in fetching data`, response);
reject(new Error('Error in fetching data'));
}
}
});
});
await page.goto('https://spasibosberbank.ru/lk_history');
await page.waitForSelector('.lk-history-list__transactions');
const data = await promise;
await page.close();
return data;
} catch (error) {
this.logger.error(error);
await page.close();
throw error;
}
}Сначала надо не забыть запустить сам браузер и разово там войти в спасибо сберовский, чтобы дальше уже использовалась подключенная авторизация.
Обработку ошибок, устаревание сессии и другое пока не делал. Как поймаю такую ошибку - буду думать как отлавливать её.
Архитектура решения
Мой личный бот реализован в виде нескольких микросервисов, которые запущены каждый в своем месте. Когда про это я напишу отдельный пост. Я выделил отдельный микросервис через nest microservice, который запускается прям на моем рабочем компе.
Сделал я это для того, чтобы у третьих лиц не было доступа к браузеру, который авторизован в моих личных сервисах. Особенно банковских. В свое время я через этот микросервис делал механизм автоматической заливки роликов на все площадки.
Архитектура решения для дзен-мани выглядит следующим образом:

Исходник диаграммы тут.
Контроллер для обработки запросов выглядит следующим образом
import { Controller } from '@nestjs/common';
import { MessagePattern } from '@nestjs/microservices';
import { MS_PUPPETEER_SERVICE_MESSAGES } from '@amorev-bot/microservices';
import { SpasiboService } from './spasibo.service';
@Controller()
export class SpasiboController {
constructor(private readonly service: SpasiboService) {}
@MessagePattern(MS_PUPPETEER_SERVICE_MESSAGES.getSpasiboData)
send(data: any) {
return this.service.fetchTransactions(data);
}
}
Внутри метода fetchTransactions уже реализована логика, показанная выше. Сам микросервис не занимается никаким хранением, кешированием и тд. На текущей версии он просто делает сразу запрос через браузер и отдает информацию. Кеширование и проверка перед лишним запуском реализуется уже на стороне основного сервиса, который будет его вызывать.
Таким образом я могу спокойно мокировать ответ микросервиса уже внутри ядра и писать обработку через jest тесты.
Получение данных для других страниц
Я хочу свой коннектор сделать таким, чтобы он мог делать запросы к другим страницам тоже. Учитывая работу виртуального браузера это можно сделать несколькими способами.
Первый способ — имитировать скролл браузера вниз и ловить новые запросы до тех пор, пока не выпадет нужный запрос с ID. Он отпадает, потому что крайне ненадежен и я бы хотел напрямую стучаться в API сервиса.
Второй способ заключается в перехвате запроса (как я писал выше) и дальше уже в отправке всех запросов самостоятельно. Для этого я перешел в network вкладку в браузере, увидел нужный мне запрос, скопировал его как curl.

После чего вставил его в phpstorm в файл с расширением .http. Шторм сразу же конвертирует в формат для своих запросов.

Дальше я по-очередно выкидываю ненужные заголовки, пока не получу минимальный вариант, который работает и который я смогу эмулировать самостоятельно. Механика такая — выкинул заголовок, сделал запрос. Если он прошел ок, то выкидываем следующий заголовок. Таким образом пришел к минимальному набору
GET https://spasibosberbank.ru/api/online/personal/loyalitySystem/transactions?page=2&cnt=100 Authorization: BearerUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36
Отправляя эти параметры я получаю успешную обработку запроса. Более того. Это сразу натолкнуло меня на мысли, что я могу сделать все еще проще — через puppeteer ловить этот запрос, забирать куки c token и refresh_token, их зашифрованно сохранить и дальше уже слать запросы напрямую с сервиса, который может использовать простой axios. Про то как этот коннектор написать опишу ниже.


